Veracode Scanner Reference
Veracode is a popular tool for scanning code repos for security issues and vulnerabilities. Veracode performs dynamic (automated penetration test) and static (automated code review) code analysis and finds security vulnerabilities that include malicious code as well as the absence of functionality that can lead to security breaches.
Prerequisites
- Before you can ingest scan results, you must perform all the Veracode prerequisites for the repo that you're scanning. If you're scanning a Java repo, for example, the Veracode documentation outlines the specific packaging and compilation requirements for scanning your Java applications.
For specific requirements, got to the Veracode docs and search for Veracode Packaging Requirements. - You also need access credentials so that STO can communicate with your Veracode instance. Harness recommends using API keys, not usernames and passwords, for your Veracode integrations
For instructions, go to the Veracode docs and search for Generate Veracode API Credentials.
Harness recommends you create text secrets for your authentication credentials — password, API key, API secret key, etc. — and access your secrets using<+secrets.getValue("my-secret")>. - The Veracode - Automated Data Load and Veracode - Activate Scenario blog posts include useful information about how to ingest Veracode scan results into Harness.
Before you begin
Docker-in-Docker requirements
Docker-in-Docker is not required for ingestion workflows where the scan data has already been generated.
You need to include a Docker-in-Docker background service in your stage if either of these conditions apply:
- You configured your scanner using a generic Security step rather than a scanner-specific template such as Aqua Trivy, Bandit, Mend, Snyk, etc.
- You’re scanning a container image using an Orchestration or Extraction workflow.
Set up a Docker-in-Docker background step
Go to the stage where you want to run the scan.
In Overview, add the shared path
/var/run.In Execution, do the following:
- Click Add Step and then choose Background.
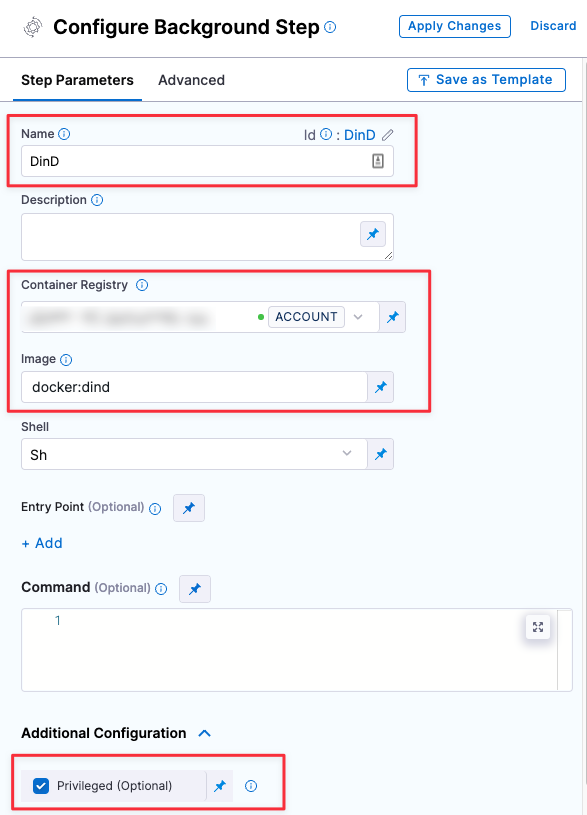
- Configure the Background step as follows:
- Dependency Name =
dind - Container Registry = The Docker connector to download the DinD image. If you don't have one defined, go to Docker connector settings reference.
- Image =
docker:dind - Under Optional Configuration, select the Privileged checkbox.
- Dependency Name =
Root access requirements
You need to run the scan step with root access if either of the following apply:
You need to run a Docker-in-Docker background service. This is required in the following scenarios only:
You're using a generic Security step to run an Orchestrated or Extraction scan, rather than a scanner-specific step such as Aqua Trivy, Bandit, etc. (not required for Ingestion scans).
You're scanning a container image using an Orchestrated or Extraction scan (not required for Ingestion scans).
You need to add trusted certificates to your scan images at runtime.
You can set up your STO scan images and pipelines to run scans as non-root and establish trust for your own proxies using self-signed certificates. For more information, go to Configure STO to Download Images from a Private Registry.
Required Settings
product_name=veracodescan_type=repositorypolicy_type— STO supports the following scan policy types for Veracode:orchestratedScan— A Security step in the pipeline runs the scan and ingests the results. This is the easiest to set up and supports scans with default or predefined settings. See Run an Orchestrated Scan in an STO Pipeline.ingestionOnly— Run the scan in a Run step, or outside the pipeline, and then ingest the results. This is useful for advanced workflows that address specific security needs. See Ingest scan results into an STO pipeline.dataLoad— A Security step downloads and ingests results from an external scanner.
product_config_name=defaultrepository_project— The name of the repo that gets scanned as shown in the Veracode UI. You use the Codebase Config object in the Harness pipeline to determine the URL of the repo to scan.
In most cases, this should match the repo name used in your Git provider.repository_branch— The branch that gets reported in STO for the ingested results. You can specify a hardcoded string or use the runtime variable<+codebase.branch>. This sets the branch based on the user input or trigger payload at runtime.
In most cases, this field should match the name of Git branch that is getting scanned.fail_on_severity- See Fail on Severity.product_auth_typeapiKey— Recommended.
Go to the Veracode docs and search for Generate Veracode API Credentials.usernamePassword— Not recommended.
product_access_id- For
usernamePasswordauthentication, this is your username. - For
apiKeyauthorization, this is your API key.
- For
product_access_token- For
usernamePasswordauthentication, this is your password. - For
apiKeyauthorization, this is your API Secret key.
- For
product_app_id— The Veracode GUID, separated with hyphens, for the target application.To determine the App ID, go to the home page for the Veracode app with the results you want to scan. The App ID is the string immediately after the port number in the URL. Thus, for the following app, you would specify
1973759.https://analysiscenter.veracode.com/auth/index.jsp#HomeAppProfile:88881:1973759The Veracode - Automated Data Load blog post describes in more detail how you can find your application IDs and project names.
Ingestion settings
The following setting is required for Security steps where the policy_type is ingestionOnly.
ingestion_fileThe results data file to use when running an Ingestion scan. You should specify the full path to the data file in your workspace, such as/shared/customer_artifacts/my_scan_results.json.In addition to ingesting scan data in the external scanner's native format, STO steps can also ingest data in SARIF and Harness Custom JSON format.
The following steps outline the general workflow for ingesting scan data into your pipeline. For a complete workflow description and example, go to Ingest Scan Results into an STO Pipeline.
Specify a shared folder for your scan results, such as
/shared/customer_artifacts. You can do this in the Overview tab of the Security stage where you're ingesting your data.Create a Run step that copies your scan results to the shared folder. You can run your scan externally, before you run the build, or set up the Run step to run the scan and then copy the results.
Add a Security step after the Run step and add the
target name,variant, andingestion_filesettings as described above.
Fail on Severity
Every Security step has a Fail on Severity setting. If the scan finds any vulnerability with the specified severity level or higher, the pipeline fails automatically. You can specify one of the following:
CRITICALHIGHMEDIUMLOWINFONONE— Do not fail on severity
The YAML definition looks like this: fail_on_severity : critical # | high | medium | low | info | none