Semgrep scanner reference
You can scan repositories using Semgrep, an open-source static analysis engine for detecting dependency vulnerabilities and other issues in your code repositories.
Before you begin
Root access requirements
You need to run the scan step with root access if either of the following apply:
You need to run a Docker-in-Docker background service. This is required in the following scenarios only:
You're using a generic Security step to run an Orchestrated or Extraction scan, rather than a scanner-specific step such as Aqua Trivy, Bandit, etc. (not required for Ingestion scans).
You're scanning a container image using an Orchestrated or Extraction scan (not required for Ingestion scans).
You need to add trusted certificates to your scan images at runtime.
You can set up your STO scan images and pipelines to run scans as non-root and establish trust for your own proxies using self-signed certificates. For more information, go to Configure STO to Download Images from a Private Registry.
Semgrep step configuration
The recommended workflow is to add a Semgrep step to a Security Tests or CI Build stage and then configure it as described below.
- UI configuration support is currently limited to a subset of scanners. Extending UI support to additional scanners is on the Harness engineering roadmap.
- Each scanner template shows only the options that apply to a specific scan. If you're setting up a repository scan, for example, the UI won't show Container Image settings.
- Docker-in-Docker is not required for these steps unless you're scanning a container image. If you're scanning a repository using Bandit, for example, you don't need to set up a Background step running DinD.
- Support is currently limited to Kubernetes and Harness Cloud AMD64 build infrastructures only.
Semgrep scanner template
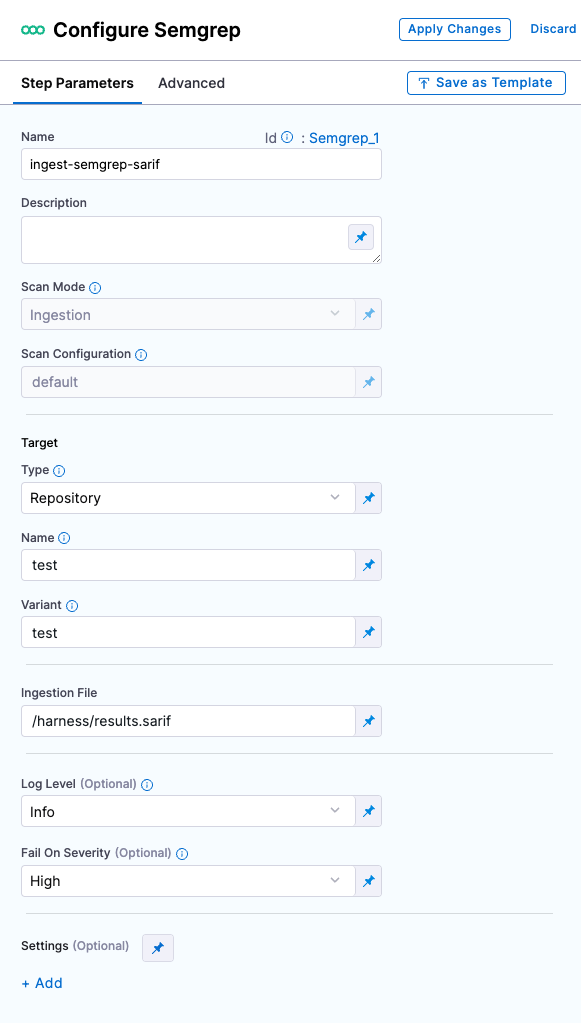
Scan
Scan Mode
The orchestration mode to use for the scan. The following list includes the UI and YAML values for the supported options.
- Ingestion Ingestion scans are not orchestrated. The Security step ingest results from a previous scan (for a scan run in an previous step) and then normallizes and compresses the results.
Scan Configuration
The predefined configuration to use for the scan. All scan steps have at least one configuration.
Target
Type
The target type to scan for vulnerabilities.
Repository Scan a codebase repo.
In most cases, you specify the codebase using a code repo connector that connects to the Git account or repository where your code is stored. For information, go to Create and configure a codebase.
Name
The Identifier that you want to assign to the target you’re scanning in the pipeline. Use a unique, descriptive name such as codebaseAlpha or jsmith/myalphaservice. Using descriptive target names will make it much easier to navigate your scan data in the STO UI.
Variant
An identifier for a specific variant to scan, such as the branch name or image tag. This identifier is used to differentiate or group results for a target. Harness maintains a historical trend for each variant.
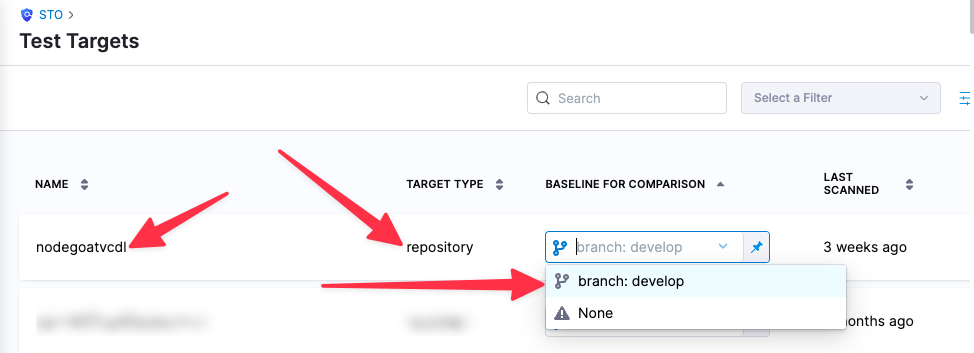
You can see the target name, type, and variant in the Test Targets UI:
Ingestion File
The results data file to use when running an Ingestion scan.
Generally an Ingestion scan consists of a scan step (to generate the data file) and an ingestion step (to ingest the data file).
In addition to ingesting scan data in the external scanner's native format, STO steps can also ingest data in SARIF and Harness Custom JSON format.
For more information, go to Ingest Scan Results into an STO Pipeline.
Log Level
The minimum severity of the messages you want to include in your scan logs. You can specify one of the following:
- DEBUG
- INFO
- WARNING
- ERROR
Fail on Severity
Every Security step has a Fail on Severity setting. If the scan finds any vulnerability with the specified severity level or higher, the pipeline fails automatically. You can specify one of the following:
CRITICALHIGHMEDIUMLOWINFONONE— Do not fail on severity
The YAML definition looks like this: fail_on_severity : critical # | high | medium | low | info | none
Additional Configuration
In the Additional Configuration settings, you can use the following options:
Advanced settings
In the Advanced settings, you can use the following options:
YAML pipeline example
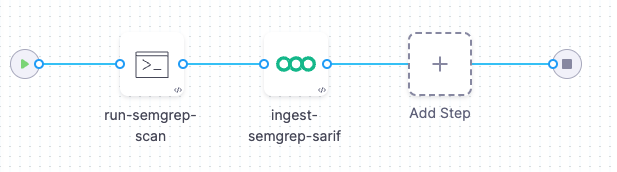
The following pipeline example illustrates an ingestion workflow. It consists of two steps:
- A Run step that uses a Semgrep container to scan the codebase defined for the pipeline and then publish the results to a SARIF data file.
- A Semgrep step that ingests the SARIF data.
pipeline:
projectIdentifier: STO
orgIdentifier: default
tags: {}
stages:
- stage:
name: semgrep-ingest
identifier: semgrepingest
type: CI
spec:
cloneCodebase: true
execution:
steps:
- step:
type: Run
name: Run_1
identifier: Run_1
spec:
shell: Sh
command: semgrep --sarif --config auto -o /harness/results.sarif /harness
envVariables:
SEMGREP_APP_TOKEN: <+secrets.getValue("semgrepkey")>
connectorRef: account.harnessImage
image: returntocorp/semgrep
resources:
limits:
memory: 4096M
- step:
type: Semgrep
name: Semgrep_1
identifier: Semgrep_1
spec:
mode: ingestion
config: default
target:
name: test
type: repository
variant: test
advanced:
log:
level: info
ingestion:
file: /harness/results.sarif
infrastructure:
type: KubernetesDirect
spec:
connectorRef: mydelegate
namespace: harness-delegate-ng
automountServiceAccountToken: true
nodeSelector: {}
os: Linux
identifier: smpsemgrep
name: smp-semgrep
properties:
ci:
codebase:
connectorRef: mygitrepodvpwa
build: <+input>