Use CI Run steps
You can use a Run step to run commands or scripts in a CI pipeline. Here are some examples of different ways you can use Run steps.
- Run tests
- Install dependencies
- Specify versions
- Clone a repo
- Run scripts
This example runs pytest, includes code coverage and produces a report in JUnit XML format.
- step:
type: Run
name: Run pytest
identifier: Run_pytest
spec:
connectorRef: account.harnessImage
image: python:latest
shell: Sh
command: |-
echo "Welcome to Harness CI"
uname -a
pip install pytest
pip install pytest-cov
pip install -r requirements.txt
pytest -v --cov --junitxml="result.xml" test_api.py test_api_2.py test_api_3.py
echo "Done"
reports:
type: JUnit
spec:
paths:
- "**/*.xml"
You can use parallelism and split_tests to define test splitting in a Run step and improve test times.
This example installs Go dependencies.
- step:
type: Run
identifier: dependencies
name: Dependencies
spec:
shell: Sh
command: |-
go get example.com/my-go-module
This example uses a Run step to select a version of Xcode.
- step:
type: Run
name: set_xcode_version
identifier: set_xcode_version
spec:
shell: Sh
command: |-
sudo xcode-select -switch /Applications/Xcode_13.4.1.app
xcodebuild -version
This example clones a GitHub repository.
- step:
type: Run
identifier: clone
name: clone
spec:
shell: Sh
command: |-
git clone https://GH_PERSONAL_ACCESS_TOKEN@github.com/ACCOUNT_NAME/REPO_NAME.git
To use this command, you would replace:
ACCOUNT_NAMEwith your GitHub account name.REPO_NAMEwith the name of the GitHub repo to clone.PERSONAL_ACCESS_TOKENwith a GitHub personal access token that has pull permissions to the target repository. Additional permissions may be necessary depending on the Action's purpose. Store the token as a Harness secret and use a variable expression, such as<+secrets.getValue("YOUR_TOKEN_SECRET")>, to call it.
Run steps are highly versatile, and you can use them to run all manner of individual commands or multi-line scripts.
For example, this step is from the Terraform notifications tutorial, and it produces output variables from Terraform values. These output variables are used by another step later in the same pipeline.
- step:
type: Run
name: Terraform Outputs
identifier: tf_outputs
spec:
connectorRef: account.harnessImage
image: kameshsampath/kube-dev-tools
shell: Sh
command: |-
cd /harness/vanilla-gke/infra
terraform init
GCP_PROJECT=$(terraform output -raw project-name)
GCP_ZONE=$(terraform output -raw zone)
GKE_CLUSTER_NAME=$(terraform output -raw kubernetes-cluster-name)
envVariables:
TF_TOKEN_app_terraform_io: <+secrets.getValue("terraform_cloud_api_token")>
TF_WORKSPACE: <+trigger.payload.workspace_name>
TF_CLOUD_ORGANIZATION: <+trigger.payload.organization_name>
outputVariables:
- name: GCP_PROJECT
- name: GCP_ZONE
- name: GKE_CLUSTER_NAME
imagePullPolicy: Always
description: Get the outputs of terraform provision
Consider creating plugins for scripts that you reuse often.
Add the Run step
You need a CI pipeline with a Build stage where you'll add the Run step. If you haven't created a pipeline before, try one of the CI pipeline tutorials.
In order for the Run step to execute your commands, the build environment must have the necessary binaries for those commands. Depending on the stage's build infrastructure, Run steps can use binaries that exist in the build environment or pull an image, such as a public or private Docker image, that contains the required binaries. For more information about when and how to specify images, go to the Container registry and image settings.
- Visual
- YAML
- Go to the Build stage in the pipeline where you want to add the Run step.
- On the Execution tab, select Add Step, and select the Run step from the Step Library.
- Configure the Run step settings and then select Apply Changes to save the step.
In Harness, go to the pipeline where you want to add the Run step. In the CI stage, add a Run step and configure the Run step settings.
- step:
type: Run
name: Run pytest # Specify a name for the step.
identifier: Run_pytest # Define a step ID, usually based on the name.
spec:
connectorRef: account.harnessImage # Specify a container registry, if required.
image: python:latest # Specify an image, if required.
shell: Sh
command: |-
# Provide your commands.
Settings
The Run step has the following settings.
Depending on the stage's build infrastructure, some settings may be unavailable or optional. Settings specific to containers, such as Set Container Resources, are not applicable when using the step in a stage with VM or Harness Cloud build infrastructure.
Name
Enter a name summarizing the step's purpose. Harness automatically assigns an Id (Entity Identifier Reference) based on the Name. You can change the Id.
Description
Optional text string describing the step's purpose.
Container Registry and Image
Container Registry and Image ensure that the build environment has the binaries necessary to execute the commands that you want to run in this step. For example, a cURL script may require a cURL image, such as curlimages/curl:7.73.0.
The Container Registry is a container registry connector, such as a Docker connector, that connects to a container registry, such as Docker Hub.
The Image is the fully-qualified name (FQN) or artifact name of the Docker image to use when this step runs commands, for example us.gcr.io/playground-123/quickstart-image.
The image name should include the tag. If you don't include a tag, Harness uses the latest tag.
You can use any Docker image from any Docker registry, including Docker images from private registries. Different container registries require different name formats:
- Docker Registry: Input the name of the artifact you want to deploy, such as
library/tomcat. Wildcards aren't supported. FQN is required for images in private container registries. - ECR: Input the FQN of the artifact you want to deploy. Images in repos must reference a path, for example:
40000005317.dkr.ecr.us-east-1.amazonaws.com/todolist:0.2. - GCR: Input the FQN of the artifact you want to deploy. Images in repos must reference a path starting with the project ID that the artifact is in, for example:
us.gcr.io/playground-243019/quickstart-image:latest.
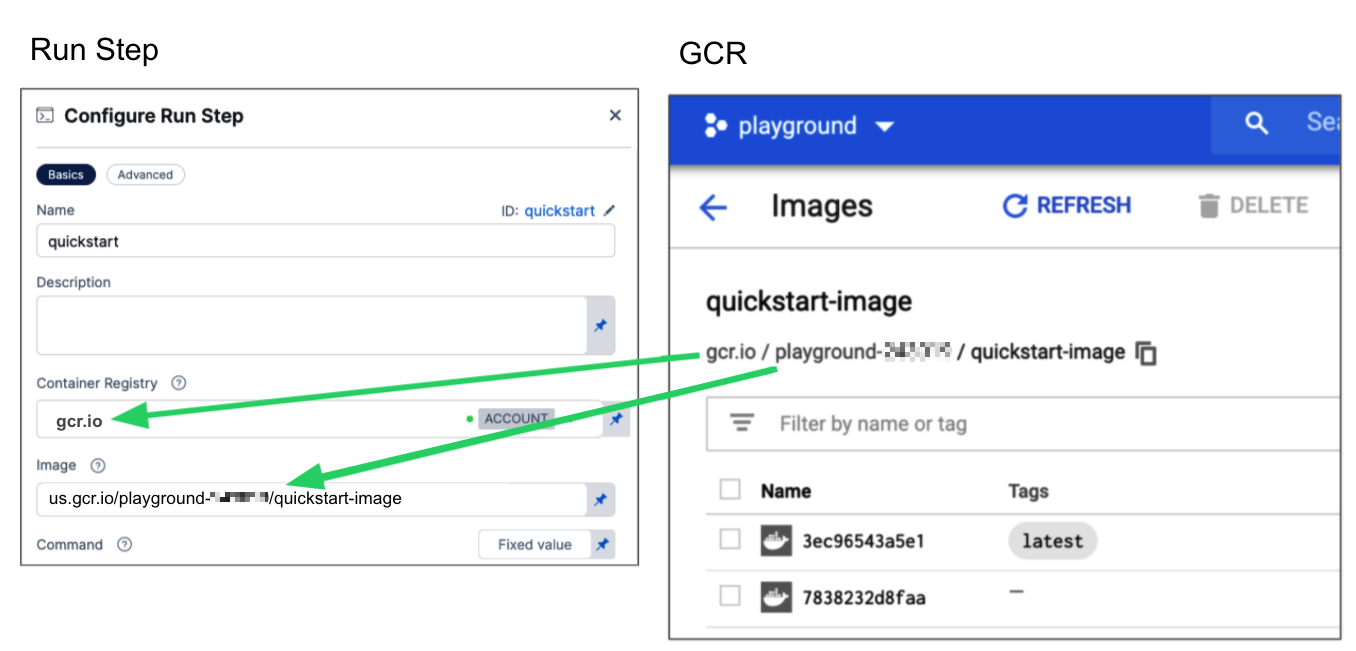
The stage's build infrastructure determines whether these fields are required or optional:
- Kubernetes cluster build infrastructure: Container Registry and Image are always required.
- Local runner build infrastructure: Container Registry and Image are always required.
- Self-hosted cloud provider VM build infrastructure: Run steps can use binaries that you've made available on your build VMs. The Container Registry and Image are required if the VM doesn't have the necessary binaries. These fields are located under Optional Configuration for stages that use self-hosted VM build infrastructure.
- Harness Cloud build infrastructure: Run steps can use binaries available on Harness Cloud machines, as described in the image specifications. The Container Registry and Image are required if the machine doesn't have the binary you need. These fields are located under Optional Configuration for stages that use Harness Cloud build infrastructure.
Shell and Command
Use these fields to define the commands that you need to run in this step.
For Shell, select the shell type. Options include: Bash, PowerShell, Pwsh (PowerShell Core), Sh, and Python. If the step includes commands that aren't supported for the selected shell type, the build fails. Required binaries must be available on the build infrastructure or through a specified Container Registry and Image.
In the Command field, enter POSIX shell script commands for this step. The script is invoked as if it were the entry point. If the step runs in a container, the commands are executed inside the container.
- Bash
- PowerShell
- Pwsh (PowerShell Core)
- Sh
- Python
This Bash script example checks the Java version.
- step:
...
spec:
shell: Bash
command: |-
JAVA_VER=$(java -version 2>&1 | head -1 | cut -d'"' -f2 | sed '/^1\./s///' | cut -d'.' -f1)
if [[ $JAVA_VER == 17 ]]; then
echo successfully installed $JAVA_VER
else
exit 1
fi
This is a simple PowerShell Wait-Event example.
- step:
...
spec:
shell: Powershell
command: Wait-Event -SourceIdentifier "ProcessStarted"
You can run PowerShell commands on Windows VMs running in AWS build farms.
This PowerShell Core example runs ForEach-Object over a list of events.
- step:
...
spec:
shell: Pwsh
command: |-
$Events = Get-EventLog -LogName System -Newest 1000
$events | ForEach-Object -Begin {Get-Date} -Process {Out-File -FilePath Events.txt -Append -InputObject $_.Message} -End {Get-Date}
You can run PowerShell Core commands in pods or containers that have pwsh installed.
In this example, the pulls a python image and executes a shell script (Sh) that runs pytest with code coverage.
- step:
...
spec:
connectorRef: account.harnessImage
image: python:latest
shell: Sh
command: |-
echo "Welcome to Harness CI"
uname -a
pip install pytest
pip install pytest-cov
pip install -r requirements.txt
pytest -v --cov --junitxml="result.xml" test_api.py test_api_2.py test_api_3.py
If the shell is Python, supply Python commands directly in command.
This example uses a basic print command.
steps:
- step:
...
spec:
shell: Python
command: print('Hello, world!')
Reference background services
You can reference services started in Background steps by using the Background step's Id in your Run step's Command. For example, a cURL command could call BackgroundStepId:5000 where it might otherwise call localhost:5000.
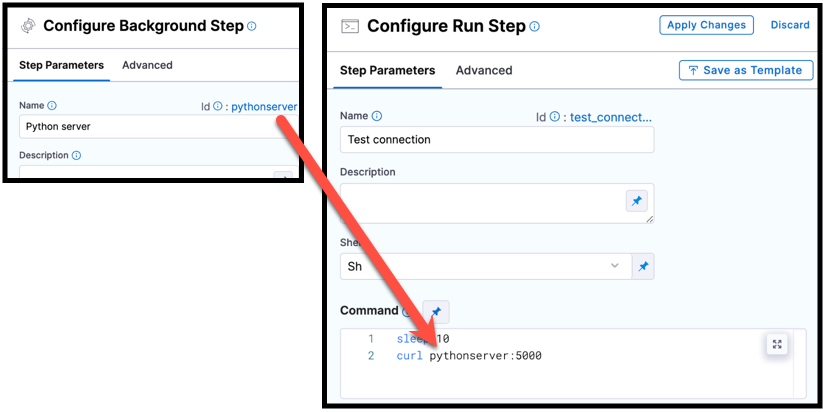
pythonscript, is used in a cURL command in a Run step.If the Background step is inside a step group, you must include step group ID, such as StepGroupId_BackgroundStepId:5000, even if both steps are in the same step group.
Scripts that produce output variables
If your script produces an output variable, you must declare the output variable in the Run step's Output Variables. For example, the following step runs a python script that defines an output variable called OS_VAR, and OS_VAR is also declared in the outputVariables.
- step:
type: Run
name: Run_2
identifier: Run_2
spec:
shell: Python
command: |-
import os
os.environ["OS_VAR"] = value
outputVariables:
- name: OS_VAR
Privileged
Enable this option to run the container with escalated privileges. This is equivalent to running a container with the Docker --privileged flag.
Report Paths
Specify one or more paths to files that store test results in JUnit XML format. You can add multiple paths. If you specify multiple paths, make sure the files contain unique tests to avoid duplicates. Glob is supported.
This setting is required for the Run step to be able to publish test results.
For example, this step runs pytest and produces a test report in JUnit XML format.
- step:
type: Run
name: Pytest
identifier: Pytest
spec:
shell: Sh
command: |-
pytest test_main.py --junit-xml=output-test.xml
reports:
type: JUnit
spec:
paths:
- output-test.xml
Environment Variables
You can inject environment variables into the step container and use them in the Command script. You must input a Name and Value for each variable.
You can reference environment variables in the Command script by name. For example, a Bash script would use $var_name or ${var_name}, and a Windows PowerShell script would use $Env:varName.
Variable values can be fixed values, runtime inputs, or expressions. For example, if the value type is expression, you can input a value that references the value of some other setting in the stage or pipeline.
Stage variables are inherently available to steps as environment variables.
Output Variables
Output variables expose values for use by other steps or stages in the pipeline.
YAML example: Output variable
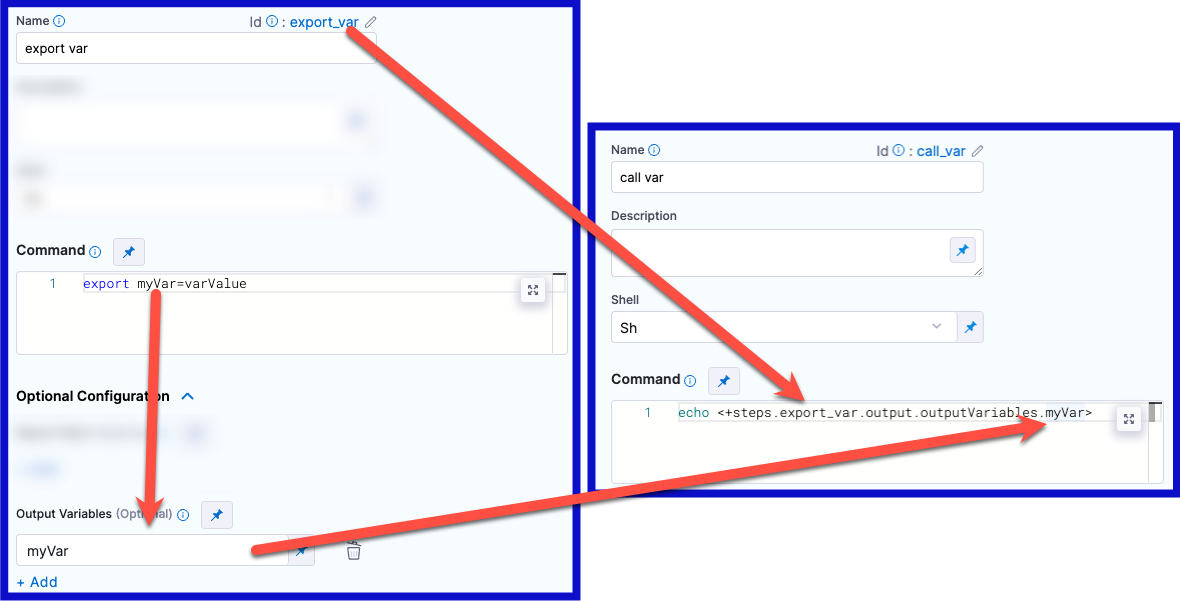
In the following YAML example, step alpha exports an output variable called myVar, and then step beta references that output variable.
- step:
type: Run
name: alpha
identifier: alpha
spec:
shell: Sh
command: export myVar=varValue
outputVariables:
- name: myVar
- step:
type: Run
name: beta
identifier: beta
spec:
shell: Sh
command: |-
echo <+steps.alpha.output.outputVariables.myVar>
echo <+execution.steps.alpha.output.outputVariables.myVar>
If an output variable value contains a secret, be aware that the secret will be visible in the build details:
- On the Output tab of the step where the output variable originates.
- In the build logs for any later steps that reference that variable.
For information about best practices for using secrets in pipelines, go to the Secrets documentation.
Create an output variable
To create an output variable, do the following in the step where the output variable originates:
In the Command field, export the output variable. For example, the following command exports a variable called
myVarwith a value ofvarValue:export myVar=varValueIn the step's Output Variables, declare the variable name, such as
myVar.
Reference an output variable
To reference an output variable in a later step or stage in the same pipeline, use a variable expression that includes the originating step's ID and the variable's name.
Use either of the following expressions to reference an output variable in another step in the same stage:
<+steps.[stepID].output.outputVariables.[varName]>
<+execution.steps.[stepID].output.outputVariables.[varName]>
Use either of the following expressions to reference an output variable in a different stage than the one where it originated:
<+stages.[stageID].spec.execution.steps.[stepID].output.outputVariables.[varName]>
<+pipeline.stages.[stageID].spec.execution.steps.[stepID].output.outputVariables.[varName]>
Early access feature: Output variables as environment variables
Currently, this early access feature is behind the feature flag CI_OUTPUT_VARIABLES_AS_ENV. Contact Harness Support to enable the feature.
With this feature flag enabled, output variables from steps are automatically available as environment variables for other steps in the same Build (CI) stage. This means that, if you have a Build stage with three steps, an output variable produced from step one is automatically available as an environment variable for steps two and three.
In other steps in the same stage, you can refer to the output variable by its key without additional identification. For example, an output variable called MY_VAR can be referenced later as simply $MY_VAR. Without this feature flag enabled, you must use an expression to reference the output variable, such as <+steps.stepID.output.outputVariables.MY_VAR>.
With or without this feature flag, you must use an expression when referencing output variables across stages, for example:
name: <+stages.[stageID].spec.execution.steps.[stepID].output.outputVariables.[varName]>
name: <+pipeline.stages.[stageID].spec.execution.steps.[stepID].output.outputVariables.[varName]>
YAML examples: Referencing output variables
In the following YAML example, a step called alpha exports an output variable called myVar, and then a step called beta references that output variable. Both steps are in the same stage.
- step:
type: Run
name: alpha
identifier: alpha
spec:
shell: Sh
command: export myVar=varValue
outputVariables:
- name: myVar
- step:
type: Run
name: beta
identifier: beta
spec:
shell: Sh
command: |-
echo $myVar
The following YAML example has two stages. In the first stage, a step called alpha exports an output variable called myVar, and then, in the second stage, a step called beta references that output variable.
- stage:
name: stage1
identifier: stage1
type: CI
spec:
...
execution:
steps:
- step:
type: Run
name: alpha
identifier: alpha
spec:
shell: Sh
command: export myVar=varValue
outputVariables:
- name: myVar
- stage:
name: stage2
identifier: stage2
type: CI
spec:
...
execution:
steps:
- step:
type: Run
name: beta
identifier: beta
spec:
shell: Sh
command: |-
echo <+stages.stage1.spec.execution.steps.alpha.output.outputVariables.myVar>
If multiple variables have the same name, variables are chosen according to the following hierarchy:
- Environment variables defined in the current step
- Output variables from previous steps
- Stage variables
- Pipeline variables
This means that Harness looks for the referenced variable within the current step, then it looks at previous steps in the same stage, and then checks the stage variables, and, finally, it checks the pipeline variables. It stops when it finds a match.
If multiple output variables from previous steps have the same name, the last-produced variable takes priority. For example, assume a stage has three steps, and steps one and two both produce output variables called NAME. If step three calls NAME, the value of NAME from step two is pulled into step three because that is last-produced instance of the NAME variable.
For stages that use looping strategies, particularly parallelism, the last-produced instance of a variable can differ between runs. Depending on how quickly the parallel steps execute during each run, the last step to finish might not always be the same.
To avoid conflicts with same-name variables, either make sure your variables have unique names or use an expression to specify a particular instance of a variable, for example:
name: <+steps.stepID.output.outputVariables.MY_VAR>
name: <+execution.steps.stepGroupID.steps.stepID.output.outputVariables.MY_VAR>
YAML examples: Variables with the same name
In the following YAML example, step alpha and zeta both export output variables called myVar. When the last step, beta, references myVar, it gets the value assigned in zeta because that was the most recent instance of myVar.
- step:
type: Run
name: alpha
identifier: alpha
spec:
shell: Sh
command: export myVar=varValue1
outputVariables:
- name: myVar
- step:
type: Run
name: zeta
identifier: zeta
spec:
shell: Sh
command: export myVar=varValue2
outputVariables:
- name: myVar
- step:
type: Run
name: beta
identifier: beta
spec:
shell: Sh
command: |-
echo $myVar
The following YAML example is the same as the previous example except that step beta uses an expression to call the value of myVar from step alpha.
- step:
type: Run
name: alpha
identifier: alpha
spec:
shell: Sh
command: export myVar=varValue1
outputVariables:
- name: myVar
- step:
type: Run
name: zeta
identifier: zeta
spec:
shell: Sh
command: export myVar=varValue2
outputVariables:
- name: myVar
- step:
type: Run
name: beta
identifier: beta
spec:
shell: Sh
command: |-
echo <+steps.alpha.output.outputVariables.myVar>
Image Pull Policy
If you specified a Container Registry and Image, you can specify an image pull policy:
- Always: The kubelet queries the container image registry to resolve the name to an image digest every time the kubelet launches a container. If the kubelet encounters an exact digest cached locally, it uses its cached image; otherwise, the kubelet downloads (pulls) the image with the resolved digest, and uses that image to launch the container.
- If Not Present: The image is pulled only if it is not already present locally.
- Never: The image is assumed to exist locally. No attempt is made to pull the image.
Run as User
If you specified a Container Registry and Image, you can specify the user ID to use for running processes in containerized steps.
For a Kubernetes cluster build infrastructure, the step uses this user ID to run all processes in the pod. For more information, go to Set the security context for a pod.
Set Container Resources
Maximum resources limits for the resources used by the container at runtime:
- Limit Memory: Maximum memory that the container can use. You can express memory as a plain integer or as a fixed-point number with the suffixes
GorM. You can also use the power-of-two equivalents,GiorMi. Do not include spaces when entering a fixed value. The default is500Mi. - Limit CPU: The maximum number of cores that the container can use. CPU limits are measured in CPU units. Fractional requests are allowed. For example, you can specify one hundred millicpu as
0.1or100m. The default is400m. For more information, go to Resource units in Kubernetes.
Timeout
Set the timeout limit for the step. Once the timeout limit is reached, the step fails and pipeline execution continues. To set skip conditions or failure handling for steps, go to:
Logs and test results
During and after pipeline runs, you can find step logs on the Build details page.
If your pipeline runs tests, you can view test reports on the Build details page.