Prometheus
Harness CV integrates with Prometheus to:
- Verify that the deployed service is running safely and performing automatic rollbacks.
- Apply machine learning to every deployment to identify and flag anomalies in future deployments.
This topic covers how to add and configure Prometheus as a Health Source for the Verify step.
Prometheus queries must include filters (enclosed in curly braces) to specify the nodes or data points you want to sample.
Prometheus queries must produce a single value (scalar). To learn more about Prometheus queries, go to QUERYING PROMETHEUS.
The Prometheus connector and health source provided by Harness are compatible with Mimir, Cortex, Thanos, Coralogix, and VictoriaMetrics platforms.
Before You Begin
Review: CV Setup Options
To use the Verify step, you will need a Harness Service Reliability Management Monitored Service. In the simplest terms, a Monitored Service is basically a mapping of a Harness Service to a service monitored by your APM or logging tool.
You can set up a Monitored Service in the Service Reliability Management module or in the Verify step in a CD stage. The process is the same.No matter where you set up the Monitored Service, once it's set up, it's available to both Service Reliability Management and CD modules.
In this topic we'll set up the Monitored Service as part of the Verify step.
Step 1: Add Verify Step
There are two ways to add the Verify step:
- When selecting the stage deployment strategy:
The Verify step can be enabled in a CD stage the first time you open the Execution settings and select the deployment strategy. When you select the deployment strategy you want to use, there is also an Enable Verification option. Select the Enable Verification option.
Harness will automatically add the Verify step. For example, here is a stage where Canary strategy and the Enable Verification option were selected.
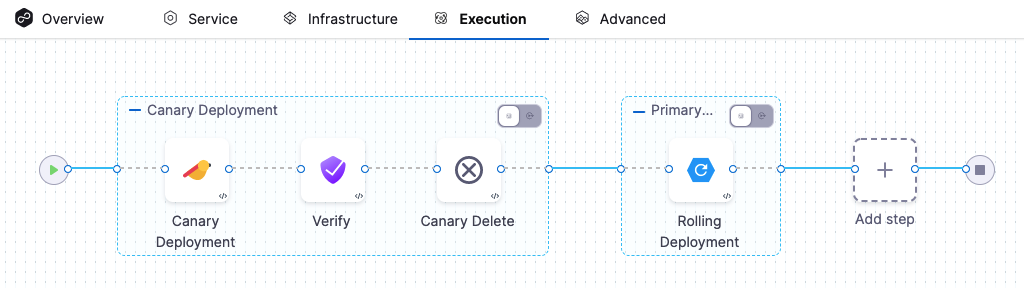
- Add the Verify step to an existing Execution setup: You can also add the Verify step to the Execution section of a CD stage in a Pipeline you previously created. Simply click Add Step after the deployment step, and then select Verify.

Step 2: Enter a Name and Timeout
In Name, enter a name for the step.
In Timeout, enter a timeout value for the step.
You can use:
wfor weeksdfor dayshfor hoursmfor minutessfor secondsmsfor milliseconds
The maximum is 53w. Timeouts can be set at the Pipeline level also.
Node filtering
Currently, this feature is behind the feature flag CV_UI_DISPLAY_NODE_REGEX_FILTER. Contact Harness Support to enable the feature.
The node filtering feature allows you to select specific nodes within your Kubernetes environment using the PodName label. This allows for focused analysis, enabling you to choose specific nodes as service instances for in-depth analysis.
Harness CV autonomously identifies new nodes as they are added to the cluster. However, the node filtering feature allows you to focus the analysis explicitly on the nodes that you want to analyze. Imagine you have a Kubernetes cluster with multiple nodes, and you want to analyze the performance of pods running on specific nodes. You want to analyze the nodes that match a certain naming pattern.
Procedure:
On the Verify settings page, expand Optional to navigate to the node filtering settings section.
(Optional) Select Use node details from CD if you want Harness CV to collect and analyze the metrics and log details for the recently deployed nodes.
Specify the Control Nodes and Test Nodes:
Control Nodes: These are the nodes against which the test nodes are compared. You can specify the control nodes to provide a baseline for analysis.
Test Nodes: These are the nodes that Harness CV evaluates and compares against the control nodes.
To specify the Control Nodes and Test Nodes, in one of the following ways:
- Type node names: Enter the names of specific nodes you want to include in the analysis.
- Use simple patterns (Regex): Define a regular expression pattern to match the nodes you want to filter. For example, if your nodes follow a naming convention such as "node-app-1", "node-app-2", and so on, you could use a pattern such as "node-app-*" to include all nodes with names starting with "node-app-".
Example: Let's say you want Harness CV to analyze the only nodes that have "backend" in their PodName label:
In the Control Nodes field, enter "backend-control-node" as the control node.
In the Test Nodes field, enter the pattern "backend-*" to include all nodes with names starting with "backend-".
Step 3: Select a Continuous Verification Type
In Continuous Verification Type, select a type that matches your deployment strategy.
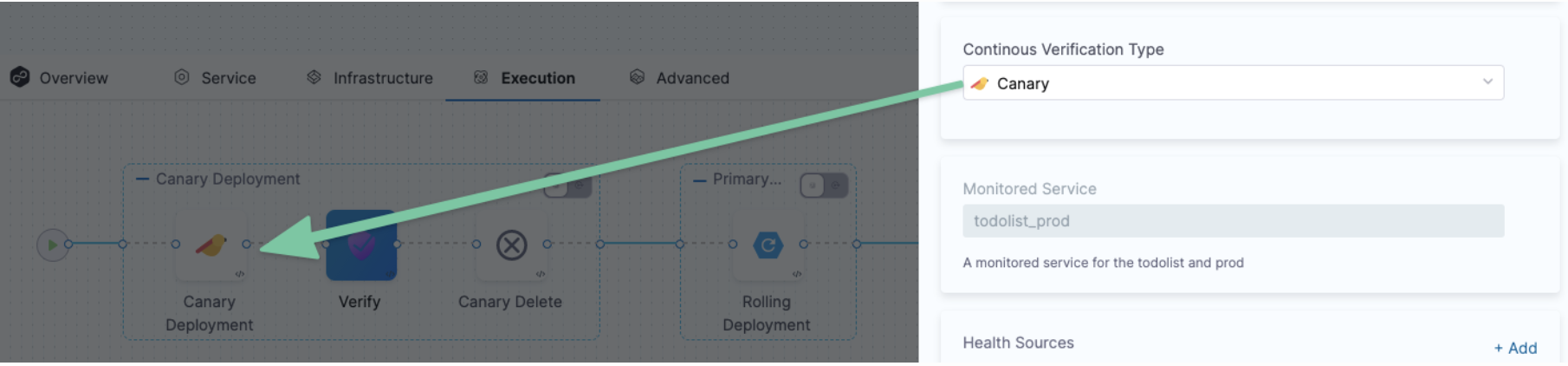
Step 4: Create a Monitored Service
In Monitored Service, click Click to autocreate a monitored service.
Harness automatically creates a monitored service using a concatenation of the service and environment names. For example, a service named todolist and an environment named dev results in a monitored service with the name todolist_dev.
The option to auto-create a monitored service is not available if you have configured either a service, an environment, or both as runtime values. When you run the pipeline, Harness concatenates the service and environment values you enter in the runtime inputs screen and generates a monitored service name. If a monitored service with the same name exists, Harness assigns it to the pipeline. If no monitored service that matches the generated monitored service name exists, Harness skips the verification step.
For example, suppose you enter the service as todolist and the environment as dev. In that case, Harness generates the monitored service name todolist_dev, checks whether a monitored service with the name todolist_dev is available, and assigns it to the pipeline. If no monitored service is available with the name todolist_dev, Harness skips the verification step.
Step 5: Add Health Sources
This option is available only if you have configured the service and environment as fixed values.
A Health Source is basically a mapping of a Harness Service to the service in a deployment environment monitored by an APM or logging tool.
In Health Sources, click Add. The Add New Health Source settings appear.
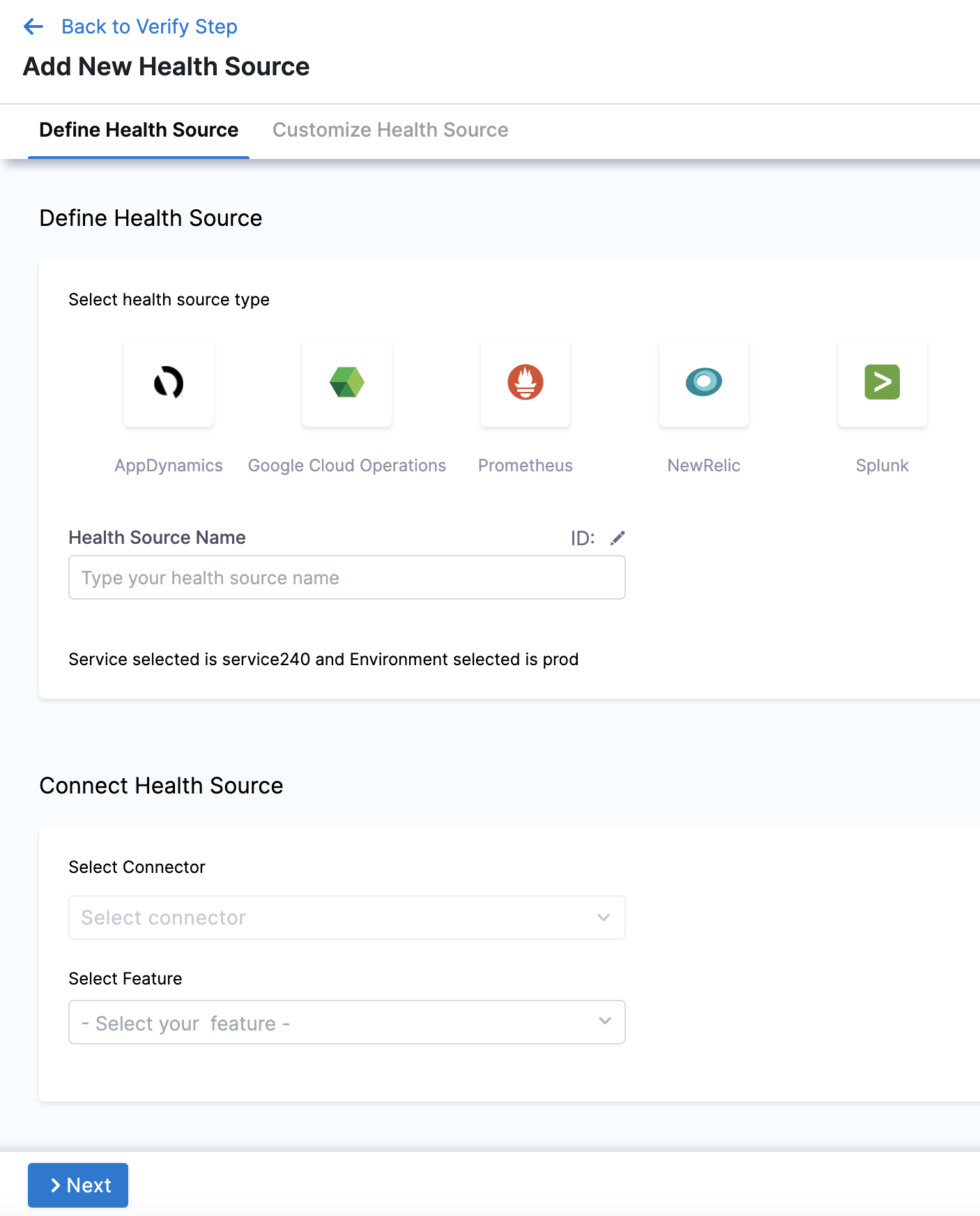
In Select health source type, select Prometheus.
In Health Source Name, enter a name for the Health Source.
Under Connect Health Source, click Select Connector.
In Connector settings, you can either choose an existing connector or click New Connector.
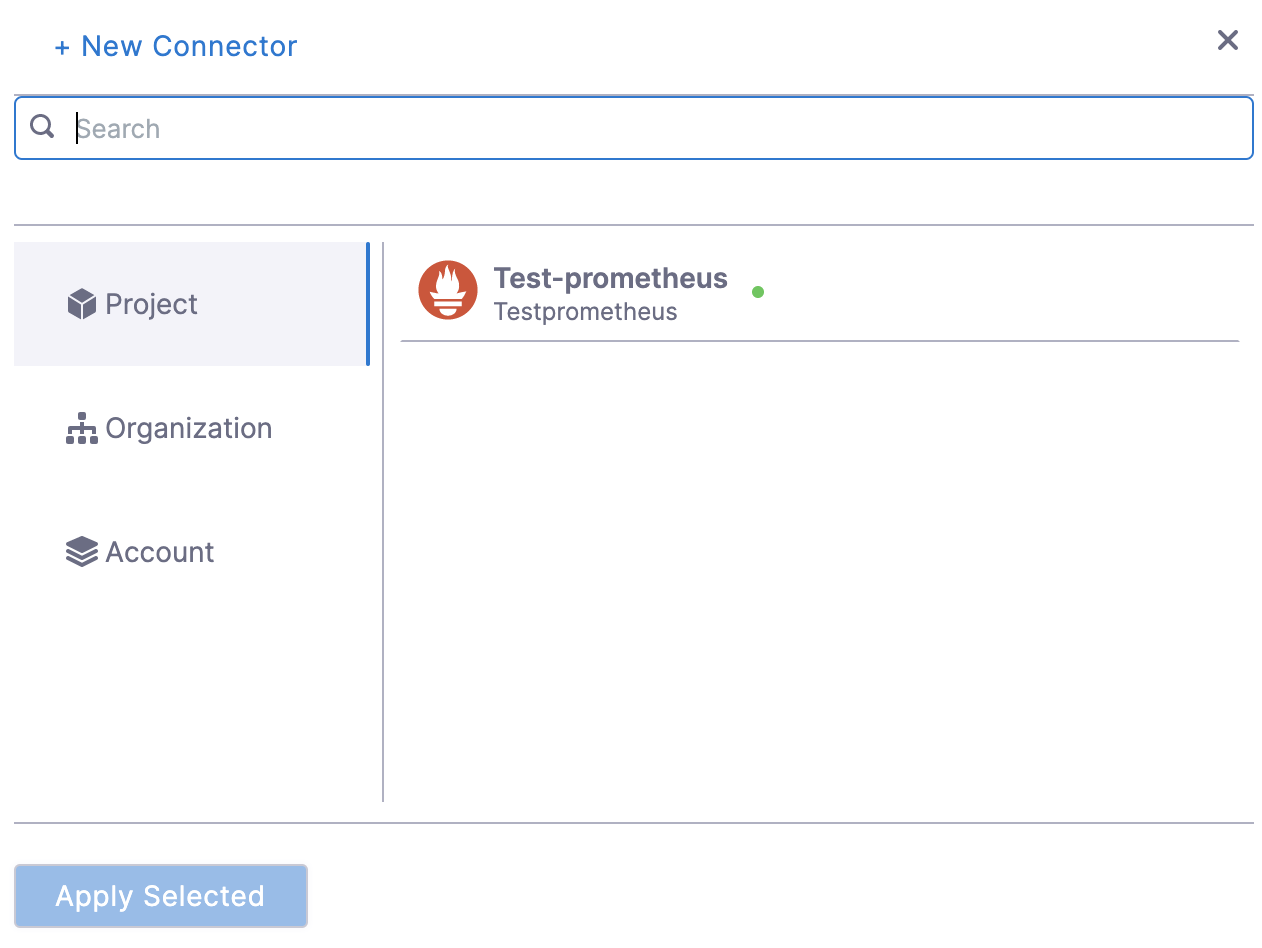
After selecting the connector, click Apply Selected. The Connector is added to the Health Source.
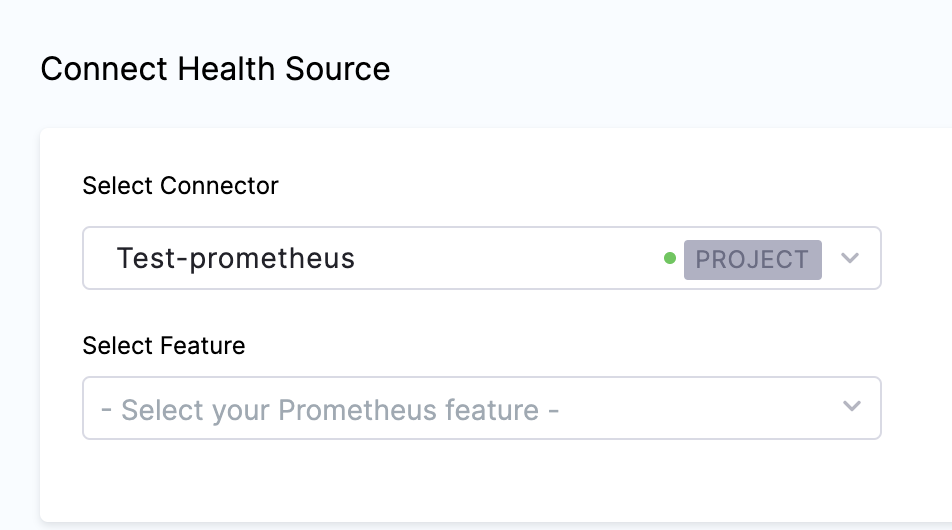
In Select Feature, select the Prometheus feature to be used.
Click Next. The Customize Health Source settings appear.
The subsequent settings in Customize Health Source depend on the Health Source Type you selected. You can customize the metrics to map the Harness Service to the monitored environment.
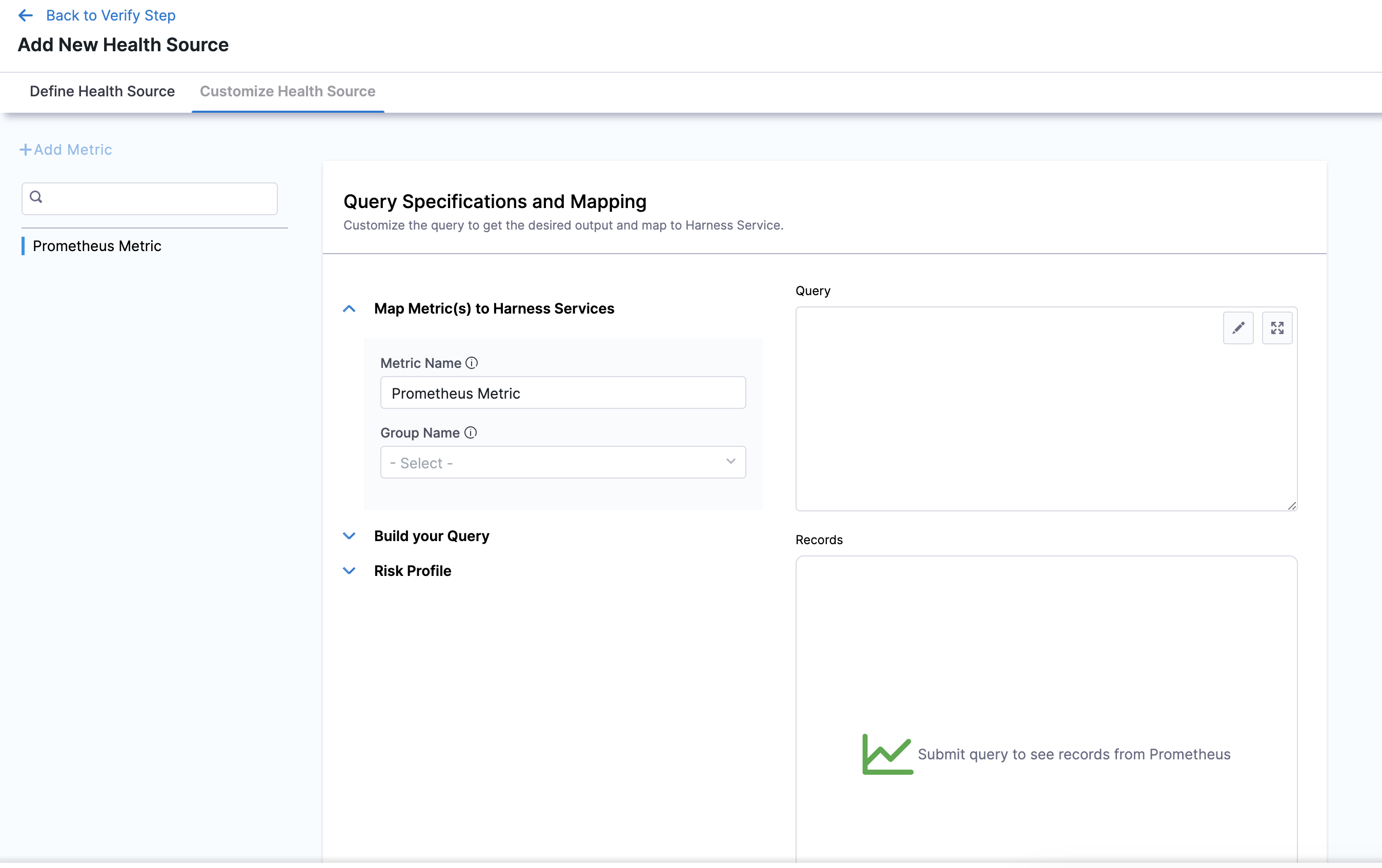
In Query Specifications and Mapping, first click Map Metric(s) to Harness Services.
Enter the desired metric name in Metric Name.
Enter a name for the Prometheus group in Group Name.
Click Build your Query drop down.
In Prometheus Metric, select the Prometheus metric.
In Filter on Environment, select a filter.
In Filter on Service, select a filter. To add more filters, click Additional Filter which is optional.
To add an aggregator for the metric, click Aggregator which is also optional.
In Assign, you can select the services for which you want to apply the metric.
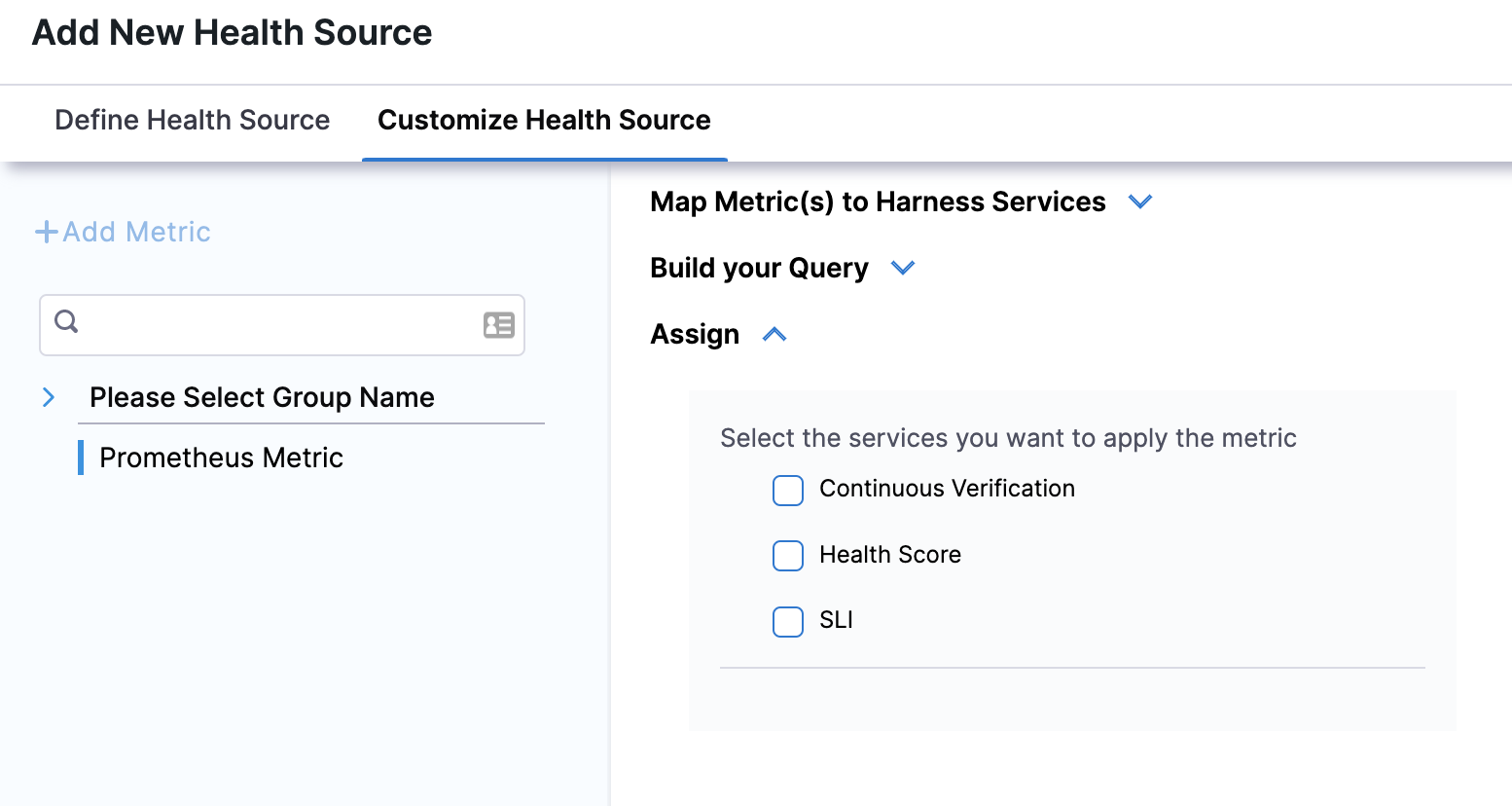
Click Submit. The Health Source is displayed in the Verify step.
You can add one or more Health Sources for each APM or logging provider.
Add Amazon Managed Service for Prometheus as health source
Currently, this feature is behind the feature flag SRM_ENABLE_HEALTHSOURCE_AWS_PROMETHEUS. Contact Harness Support to enable the feature.
Harness now supports Amazon Managed Service for Prometheus as health source. To select Amazon Managed Service for Prometheus as health source:
In Health Sources, click Add.
The Add New Health Source settings appear.In Select health source type, select Prometheus.
In Health Source Name, enter a name for the Health Source.
Under Connect Health Source > Via Cloud Provider, select Amazon web services.
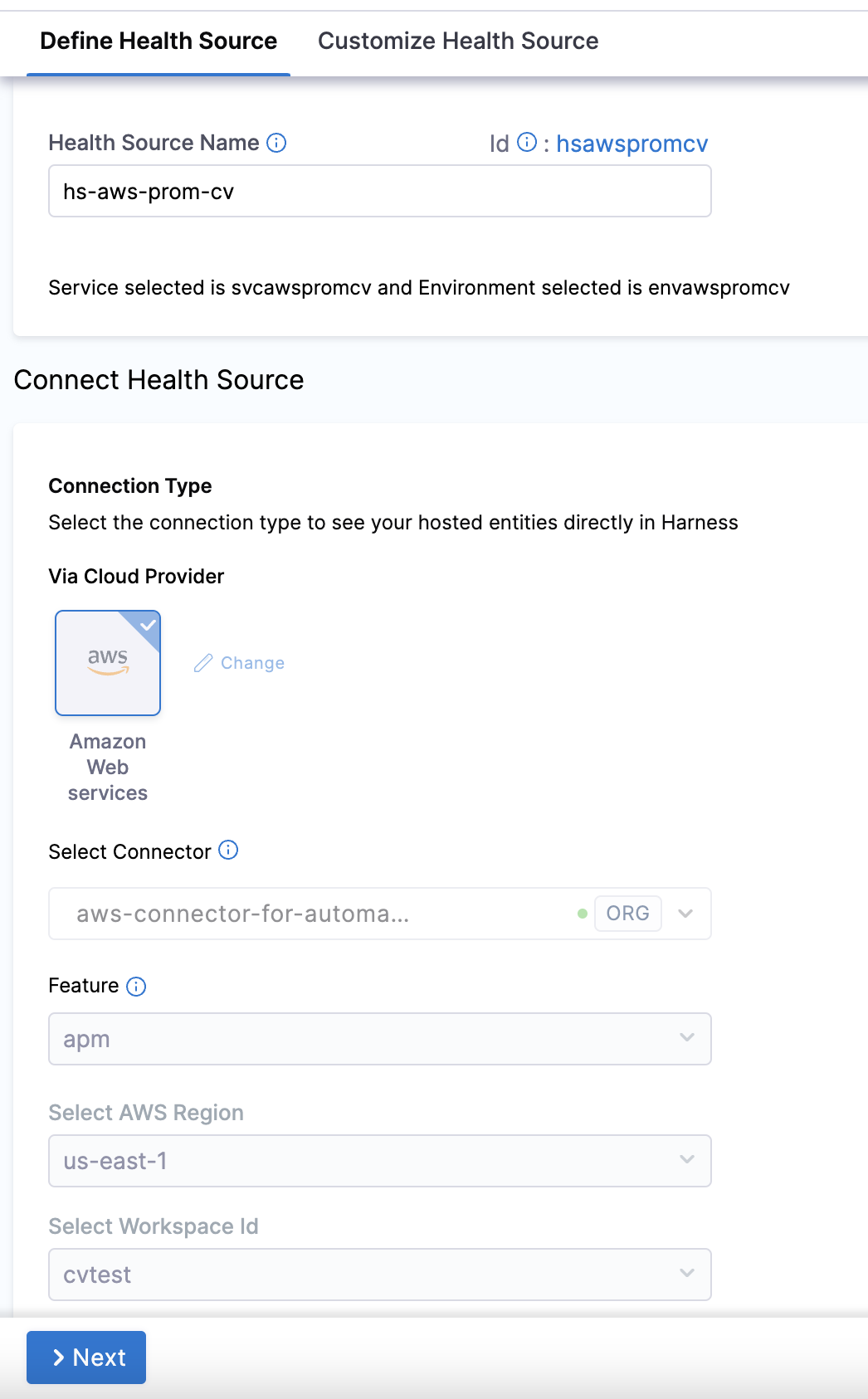
Under Connect Health Source, click Select Connector.
In Connector settings, you can either choose an existing connector or click New Connector.
In the Select Feature field, select the Prometheus feature that you want to use.
In the Select AWS Region field, select the appropriate region.
In the Select Workplace Id field, select the appropriate workplace id.
Click Next. The Customize Health Source settings appear.
You can customize the metrics to map the Harness Service to the monitored environment in Query Specifications and Mapping settings.The subsequent settings in Customize Health Source depend on the Health Source Type you selected. Click Map Queries to Harness Services drop down.Click Add Metric.
Enter a name for the query in Name your Query.
Click Select Query to select a saved query. This is an optional step. You can also enter the query manually in the Query field.
Click Fetch Records to retrieve the details. The results are displayed under Records.
Step 6: Select Sensitivity
In Sensitivity, select High, Medium, or Low based on the risk level used as failure criteria during the deployment.
Step 7: Select Duration
Select how long you want Harness to analyze and monitor the logs/APM data points. Harness waits for 2-3 minutes to allow enough time for the data to be sent to the APM/logging tool before it analyzes the data. This wait time is a standard with monitoring tools.
The recommended Duration is 10 min for logging providers and 15 min for APM and infrastructure providers.### Step 8: Specify Artifact Tag
In Artifact Tag, use a Harness expression.
The expression <+serviceConfig.artifacts.primary.tag> refers to the primary artifact.
Option: Advanced Settings
In Advanced, you can select the following options:
Step 9: Deploy and Review Results
After setting up the Verify step, click Apply Changes.
Click Run to run the pipeline.
In Run Pipeline, select the tag for the artifact if a tag was not added in the Artifact Details settings.
Click Run Pipeline.
When the Pipeline is running, click the Verify step.
You can see that the verification takes a few minutes.
Once verification is complete, the Verify step shows the following:
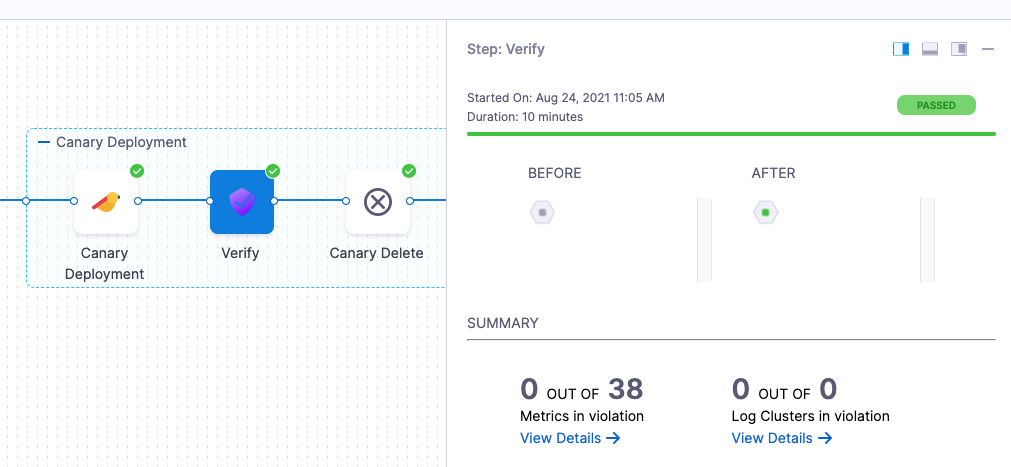
The risk level might initially display a number of violations, but the red and orange colored host often change to green over the duration.
Summary
The Summary section shows the number of logs that are in violation.
Console View
Click Console View or simply click View Details in Summary to take a deeper look at verification.
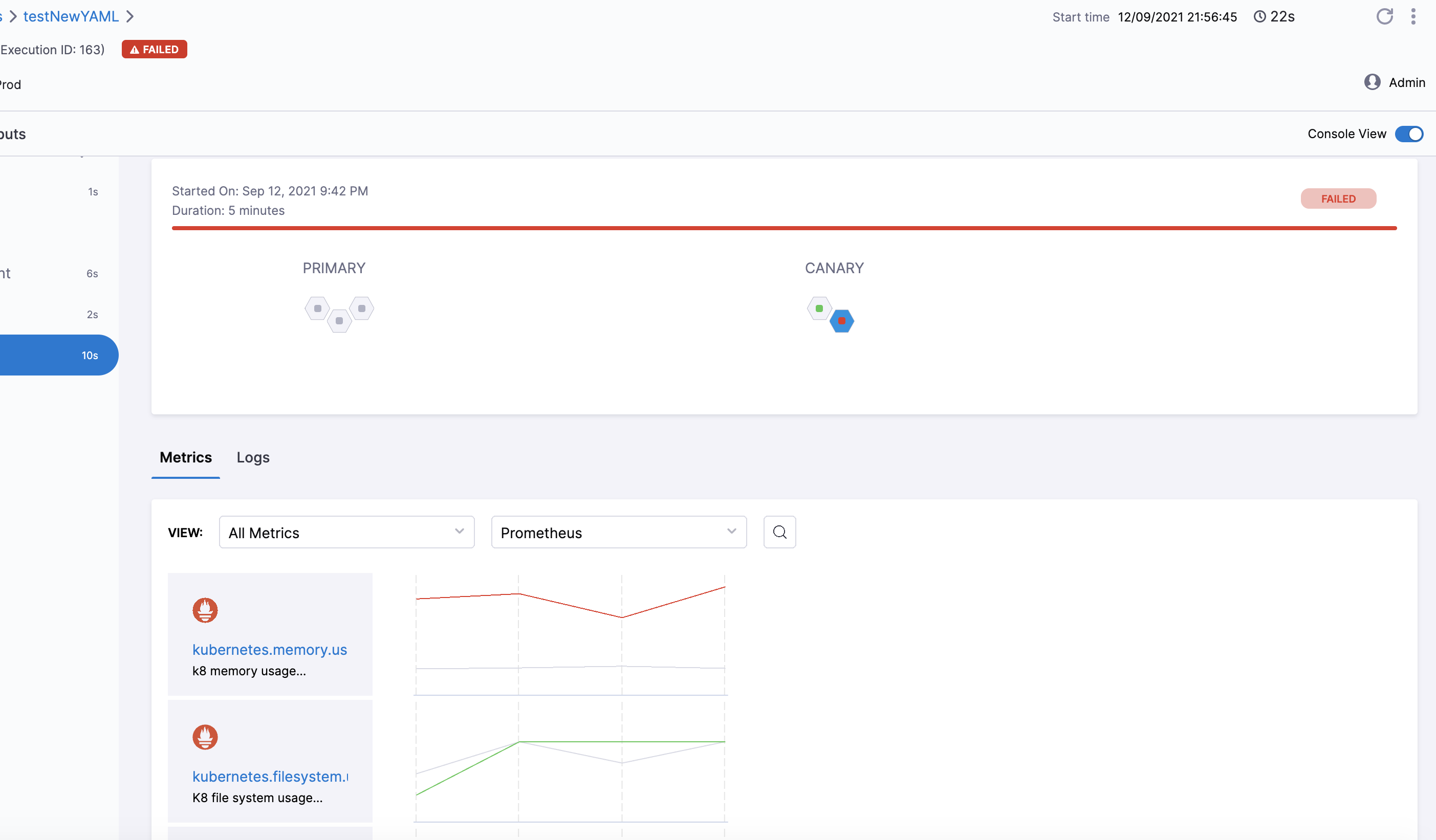
You can use the search option to search for any specific metric or transaction you want.
Set a pinned baseline
Currently, this feature is behind the feature flag SRM_ENABLE_BASELINE_BASED_VERIFICATION. Contact Harness Support to enable the feature.
You can set specific verification in a successful pipeline execution as a baseline. This is available with Load Testing as the verification type.
Set successful verification as a baseline
To set a verification as baseline for future verifications:
In Harness, go to Deployments, select Pipelines, and find the pipeline you want to use as the baseline.
Select the successful pipeline execution with the verification that you want to use as the baseline.
The pipeline execution is displayed.
On the pipeline execution, navigate to the Verify section, and then select Pin baseline.
The selected verification is now set as the baseline for future verifications.
Replace an existing pinned baseline
To use a new baseline from a pipeline and replace the existing pinned baseline, follow these steps:
In Harness, go to Deployments, select Pipelines, and find the pipeline from which you want to remove the baseline.
Select the successful pipeline execution with the verification that you have previously pinned as the baseline.
On the pipeline execution, navigate to the Verify section, and then select Pin baseline.
A confirmation alert message appears, asking if you want to replace the existing pinned baseline with the current verification. After you confirm, the existing pinned baseline gets replaced with the current verification.